Splunk Architecture
Splunk Data Pipeline

Input
- collects and consumes data from a variety of sources
- the sources can be forwarded data, uploaded data, network data, scripts, api ...
- splunk doesn't look at the contents of the data, it just passes it to the parsing phase
Parsing
- happens on the indexer or heavy forwarder
- examines, analyzes and transforms the data, identifies timestamps in the data, and annotates the data with metadata
Indexing
- Writes the data to indexes on disk in the form of flat files stored in buckets which are just directories on the filesystem
- Data divided into events. Writes the data to the disk in "buckets"
Search
- User ineteraction with the data, including searching, building reports, alerting, graphing, and dashboarding
Splunk Platform
Keep in mind, though, that Splunk has other products for IT Service Intelligence, SOAR (Security Orchestration, Automation, and Response), and more.
Splunk Enterprise
With Splunk Enterprise, you either install Splunk on-premises or datacenter in your facility, or in the cloud without specificlly using Splunk Cloud. This works very well for organizations that have both on-premises and cloud based systems, as well as for multi-cloud solutions. A Splunk Enterprise deployment is made up of Splunk components.
Splunk Components: Installations of Splunk Enterprise that are configured to perform specific actions on the Splunk Data Pipeline.
- Search Head: The main interface for searching and analyzing data.
- Indexer: Indexes and stores data on disk.
- Forwarder: Forwards data from source systems to either indexers or search heads.
In a small deployment of Splunk, the search head and indexer can be the same component.
Two main types of forwarders:
- Universal Forwarder: a very lightweight agent, sits on a data source and forwards data
- Heavy Forwarder: a more powerful agent, sits on a data source and forwards data, and also indexes data
Splunk Architecture
S1/S11 Architecture(small deployment)
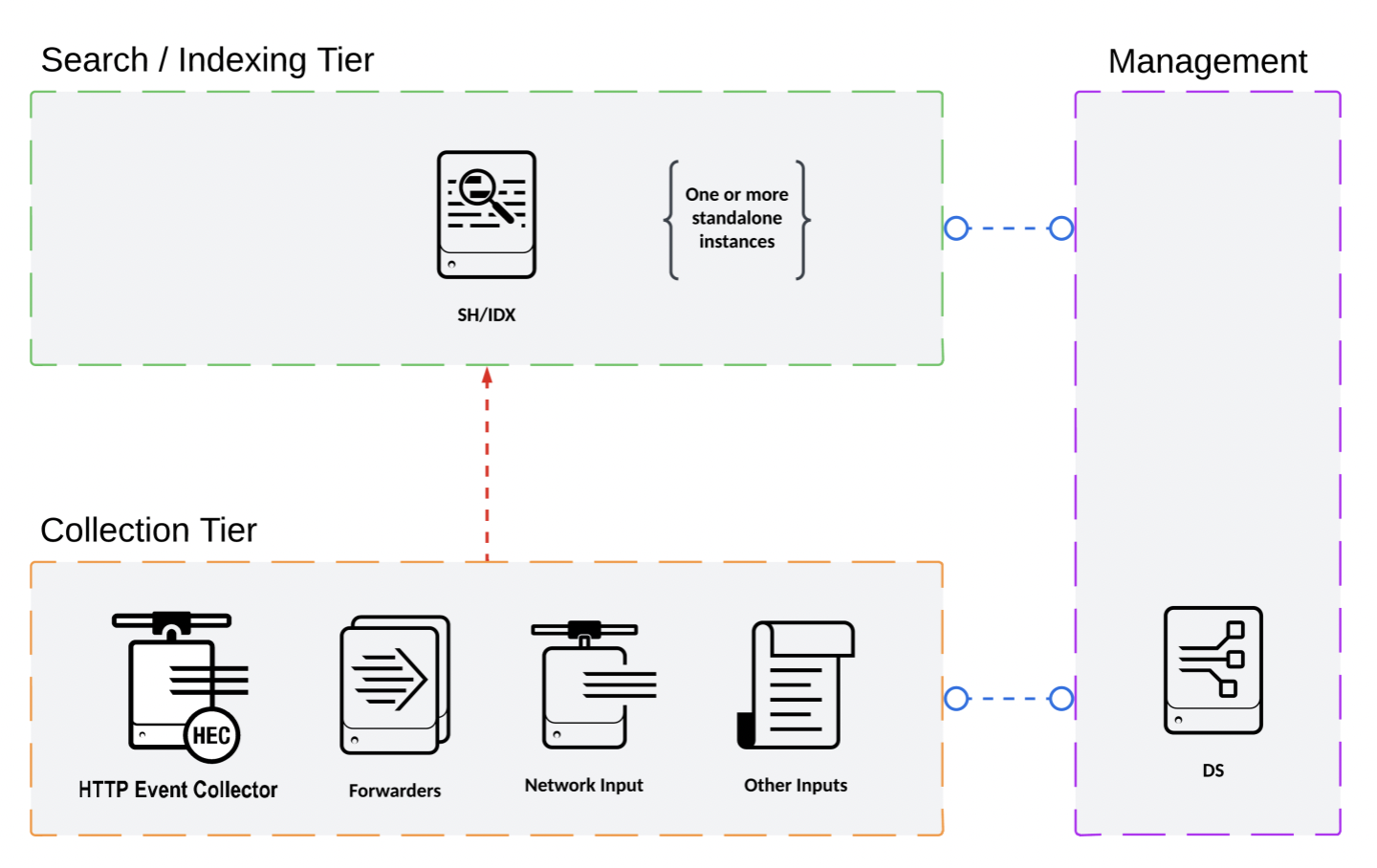
- Search Head and Indexer are the same Splunk component
- Daily data ingest up to 500GB
- Small number of users
- recommends S1 for non-critical data, there is no data replication or any kind of fault tolerance or load balancing
s1(single server deployment) with three tiers:
- Searching and Indexing tier: search head / indexer combination
- Collection tier: the data gets collected and forwarded
- Management tier
C1/C11 Architecture(Distributed Clustered Deployment - Single Site)
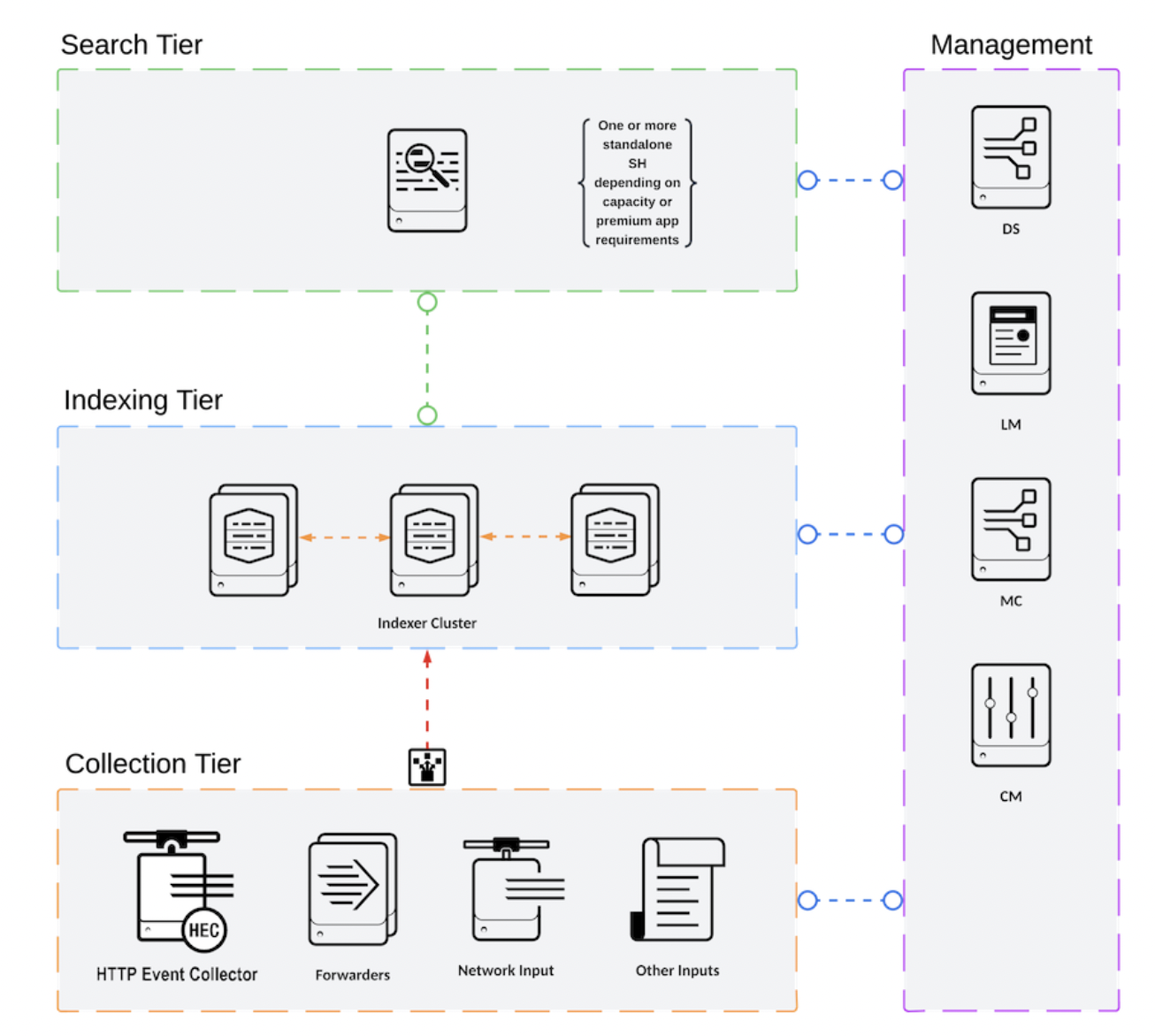
- decouple the search head and indexer
- One or more stand-alone(not clustered) search heads
- an indexer cluster with data replication, and an indexer cluster manager which manages data replication among all the indexers in a cluster
- multiple, load balanced collection inputs
- good for disaster recovery and search speed
The distributed clustered architecture environment for a single site.
- search tier
- indexing tier
- collection tier
- management tier
C3/C13 Architecture(Distributed Clustered Deployment with search head clustering - Single-Site)
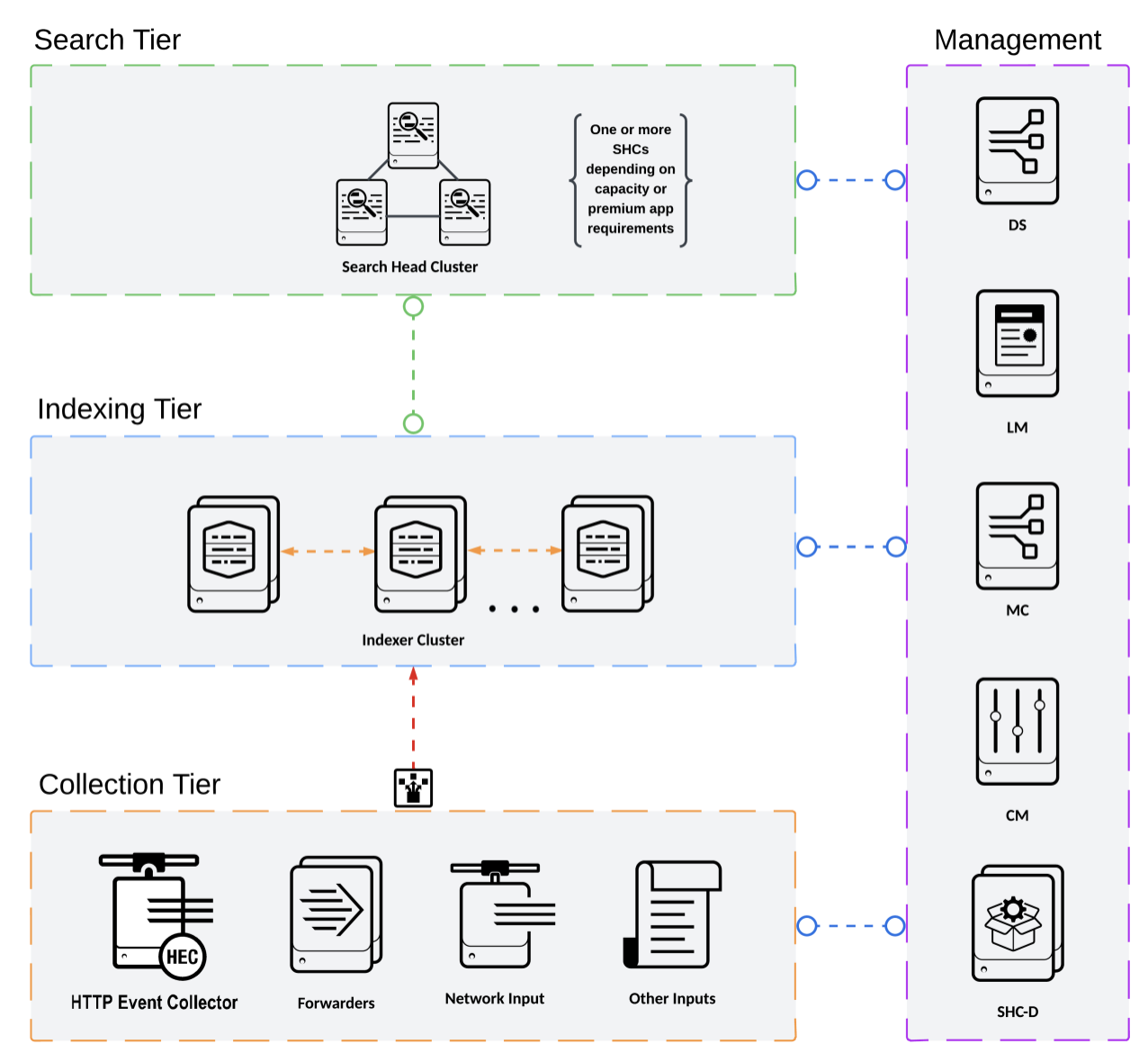
It's the same basic architecture as C1/C11, but with the addition of search head clustering.
- Search head cluster, and a deployer governs the members of the search head cluster which distributes apps, files and configuration updates to all of the members of the cluster through a configuration bundle
- one of the members of the cluster is assigned to be the search head cluster captain, it schedules jobs and replication activities among the cluster
- others are the same as in C1/C11
More Splunk Validated Architectures can be found here.
Splunk Cloud Platform
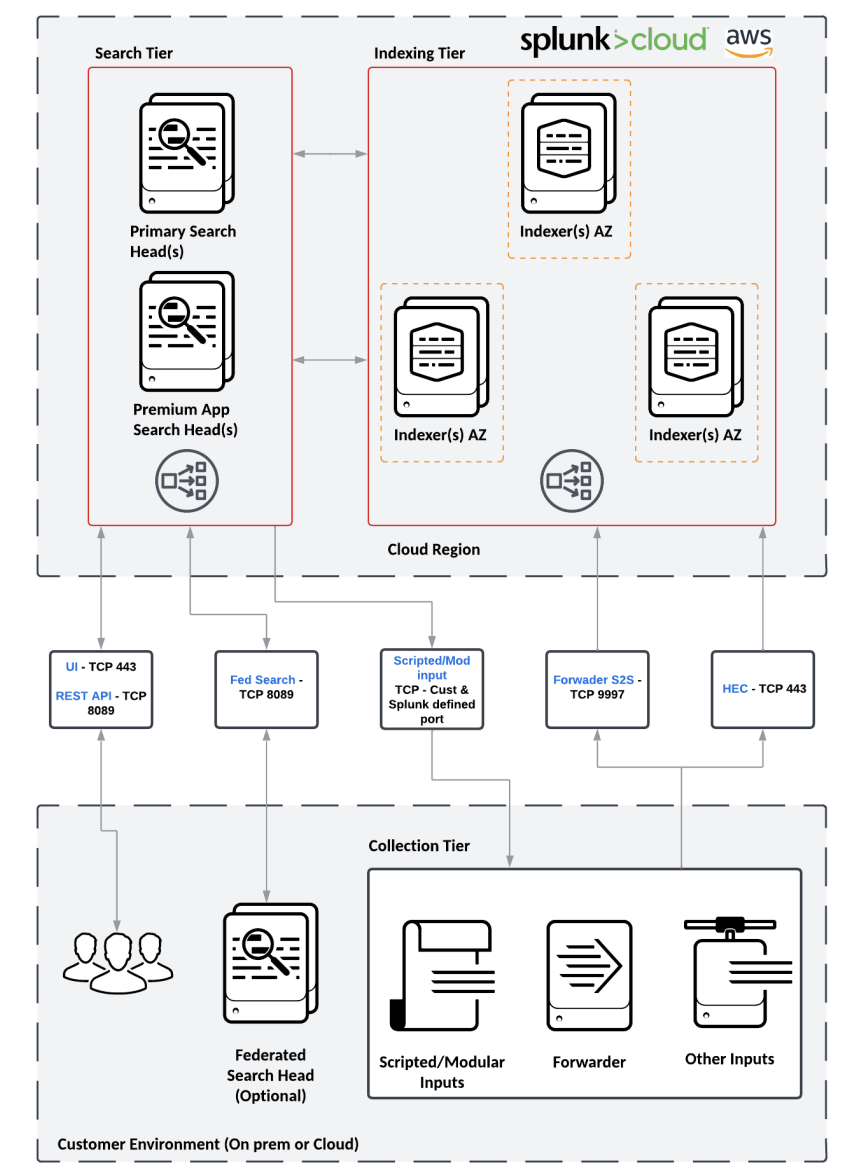
Splunk Cloud Platform is a cloud-based service where Splunk manages the infrastructure, providing most of the benefits of a Splunk Enterprise deployment, with a few key differences(collection tier).
There are two cloud experiences:
- Classic
- Victoria: new customers will be on Victoria which is hosted on AWS
Splunk cloud is licensed through subscription types(subscription based):
- workload-based subscription is the default, it's based on resource capacity used, not data volume ingested, doesn't meter ingestion, can purchase additional capacity to increase performance, can purchase units of storage blocks for different data retention needs
- ingest-based subscription, It requires an exception, similar to the Splunk Enterprise license, it's based on the volume of uncompressed data to index on a daily basis, it includes a fixed amount of data storage and can purchase additional storage as needed
Apps in Splunk Cloud
- Only vetted and compatible apps
- Some apps can be self installed through the app browser; others require a support ticket to be submitted
- Private apps are supported, but are vetted by Splunk
You do not have access to the Command Line Interface (CLI) or the underlying infrastructure. This means you will not be able to edit configuration files (.conf) or perform any CLI functions without submitting a support ticket to Splunk.
Direct data ingestion, such as TCP or syslog, is not allowed. However, you can still ingest this data; you just need to use a forwarder.
How Splunk Stores Data
Index
Index is a repository for splunk data, when splunk processes raw incoming data, it adds that data to indexes, indexes map to places on the disk which calls buckets. Splunk has several built-in indexes, the
$SPLUNK_HOME/var/lib/splunk/defaultdbis called main index,_internalindex stores internal logs, we can create additional indexes as needed.Splunk transforms incoming data into events, and stores it in indexes.
An event is just a single row of data with a bunch of key value pairs or fields.
Event
- An event is a single row of data, made up of fields
- Events have fields, which are key=value pairs. Splunk automatically looks for clear “key=value” entries in the data and creates fields. Splunk also looks for common key/value pairings that don’t necessarily have an equal sign
- Splunk adds default fields to all events, the default fields are all required
_time: a timestamp value to events in Unix time regardless of how the time is already stored in the original data, it converts it to Unix time. If the data doesn't have time information, then splunk uses the time that the data was indexed for the time field.index: the index in which splunk is storing the datahost: the hostname or ip address of the source systemsource: the name of the file, stream, or other input from which the event originatessourcetype: the format of the data, for example, a cisco syslog will come in as a source typecisco_syslog, a csv file will come in as a source typecsv.
Bucket
An index contains compressed raw data and associated index files. These index files are spread out into different directories depending on their age, we can set their age in a configuration file. Splunk calls these directories buckets, there are five types of buckets in addition to a fishbucket:
- Hot bucket: newly indexed data, it's actively written to and searched, it's the data that's most available to a search head. After a certain amount of time, the data ages out into the warm bucket. An index has one or more hot buckets.
- Warm bucket: The warm bucket has no active writing, then the data is aged and rolled to a cold bucket. An index has many warm buckets.
- Cold bucket: Buckets rolled from warm and moved to a different location. An index has many cold buckets.
- Frozen bucket: splunk deletes frozen buckets by default, but we can choose a different place to store them for archival purposes.
- Thawed bucket: when restoring from a frozen bucket(archive), the data is thawed into a thawed bucket.
The bucket ages can be set by modifying the configuration file index.conf.
The default directories of the buckets are:
- Hot bucket:
$SPLUNK_HOME/var/lib/splunk/defaultdb/db/* - Warm bucket:
$SPLUNK_HOME/var/lib/splunk/defaultdb/db/* - Cold bucket:
$SPLUNK_HOME/var/lib/splunk/defaultdb/colddb/* - Frozen bucket: location that you specify for archival purposes
- Thawed bucket:
$SPLUNK_HOME/var/lib/splunk/defaultdb/thaweddb/*
SmartStore
As the data volume of a deployment increases, the demand for storage often exceeds the demand for compute resources. SmartStore enables you to manage your indexer storage and compute resources cost-effectively by allowing you to scale these resources independently.
- SmartStore allows you to use remote object stores like AWS S3, Azure Blob Storage, GCP Cloud Storage, etc
- Most data resides on remote storage while the indexer maintains a local cache(hot buckets)
Splunk Enterprise Licensing
Two types of enterprise Licensing Volume-based and Infrastructure.
Volume-based
- Based on your data indexed per day, not data stored
- Daily indexing volume is measured from midnight to midnight by the clock on the license manager
Other things that do not count against your license
- Splunk internal log data
- Duplicate data
- Metadata
License manager can be your search head, or a separate license server.
Licenses volume of 100GB per day or higher, if you exceed your licensed daily volume on any one calendar day, you get a warning, but search is not disabled
Licenses volume of less than 100GB per day, if you generate 45 license warnings in a 60 day period, you are in violation, and that license stack will not be searchable. You need to contact Splunk to reset that license.
Infrastructure
- Based on virtual CPUs(vCPU)
- Physical or logical core, virtual core, etc
- Splunk uses the CPUs reported by the OS
- All search heads and indexers count towards vCPU capacity
Which components need a license?
In a distributed environment, most Splunk Enterprise instances need access to an enterprise license (anything that indexes data). The exception is heavy forwarders, which only need a forwarder license, unless they are also indexing data, in which case they need enterprise licenses.
The ideal way is to set up a license master and have all of the Splunk instances in your environment talk to the master to get their licenses.
A collection of licenses whose individual licensing volume amounts aggregate to serve as a single unified amount of indexing volume is called a stack.
License pooling
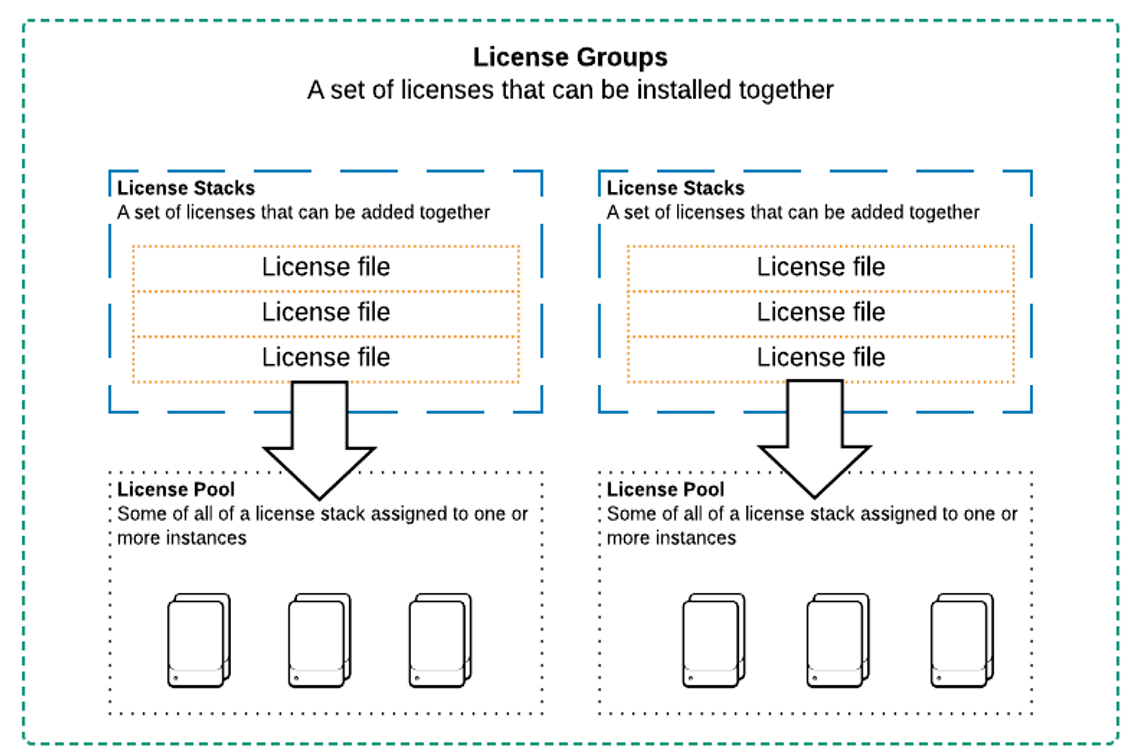
LICENSE GROUPS are sets of license stacks. A stack can only be a member of one group, and only one group can be “active” at any given time. The license groups are:
- Enterprise/Sales Trial Group: Allows stacking of purchased enterprise licenses
- Enterprise Trial Group: Default group. Cannot stack licenses
- Free Group: No stacking
- Forwarders Group: No stacking
LICENSE POOLS
- License pools are created from license stacks
- Pools are sized for specific purposes
- Managed by the license manager
- Indexers and other Splunk Enterprise components are assigned to a pool
- Splunk recommends not assigning forwarders to a license pool, since they have unique license types
Configuration Files
- Everything Splunk does is governed by configuration files
- Configuration files are stored in
/etc, and they have the.confextension - Configuration files are layered
- You can have
.conffiles that have the same name in different directories - Splunk determines which one to use based on the current app
- Use
btoolto determine which.conffile is being used
- You can have
- The
/etc/<app>/defaultdirectory contains preconfigured versions of.conffiles - The
/etc/<app>/localdirectory is where custom configurations are stored
Configuration File Structure:
# text file
[Stanza]
Attribute = Value
[Stanza]
Attribute = ValueSplunk Apps and Add-ons
Apps extend Splunk’s functionality, they enhance the user experience with built in dashboards, reports, alerts, saved searches, data models, conf files, etc. An app is a collection of Splunk configuration files, views, knowledge objects, and sometimes add-ons.
Add-ons primarily support apps, they enrich the incoming data with tags, data models, datasets, etc. An add-on is a subset of an app and specifies data collection, but doesn't usually have visualizations because they are part of the larger app.
- Apps and add-ons can be created by individuals, third party companies, Splunk, or vendors.
- Apps and add-ons that are built by Splunk carry the ”Splunk Built” logo
- Apps and add-ons that are certified by Splunk carry the “Splunk Certified” logo